

Abstinence: In the context of addiction, abstinence refers to not taking or taking part in the substance or activity that a person is addicted to. Some, but not all, treatments for addiction are abstinence-focused. For example, if a person is addicted to alcohol, their treatment goal might be to not consume any alcohol at all in the future.
ACE Model: A twin study model where variance for a certain trait is broken down into three factors: additive genetic factors (A), common environmental factors (C) and unique environmental factors (E).
- Additive genetic factors (A) are traits determined entirely by genes. Monozygotic (MZ; identical) twins have identical genes, and thus a correlation of 1.0. Dizygotic (DZ; fraternal) twins have a correlation of 0.5.
- Common environmental factors (C) are influences that both twins have in common, such as family environment. These correlate to 1.0 for both MZ and DZ twins.
- Unique environmental factors (E) are influences experienced by only one twin, such as unique friends or experiences. There is zero correlation in both MZ and DZ twins.
Neale and Cardon, 1992.
Actor-Observer Effect : The tendency to attribute our own behavior to situational causes and the behavior of others to personal factors.
Akaike Information Criteria: A measure of model fit that adjusts for the simplicity of the model. The lower the score, the better the model.
Adapted from Kline, 2005: Principles and Practice of Structural Equation Modeling.
Alcohol Use Disorder (AUD): A mental health disorder included in the DSM-5 characterized by a problematic pattern of alcohol use that leads to distress or impairment in various aspects of a person’s life. AUD is the formal diagnostic label for an alcohol addiction. Symptoms of AUD can include withdrawal (physical symptoms such as nausea, shakes, or seizures that occur after stopping alcohol consumption), tolerance (needing to consume more and more alcohol to feel the same effects of alcohol previously experienced with a lower dose), and craving (a strong desire to drink that makes it difficult to think of anything else).
Alcohol Use Disorders Identification Test (AUDIT): A standardized measure that uses a 10-point scale to screen and identify people at risk of alcohol problems,
Saunders, Aasland, Babor, De La Fuente, & Grant, 1993.
Analysis of Covariance (ANCOVA): Similar to an ANOVA, ANCOVA examines whether the means of a dependent variable differ between categories of an independent variable, but an ANCOVA also takes into account the effect of known covariates. For example, researcher run a study where they assign people to one of three different weight-loss programs (categories of the independent variable). At the end of the program, they compare the programs based on the average number of pounds the participants in each group lost (the dependent variable). However, because the researchers know that age and gender can have an effect on weight loss (i.e., they are covariates), the researchers use an ANCOVA that takes into account each person’s age and gender when determining the overall effect of the weight-loss programs in comparison to each other.
Analysis of Variance (ANOVA): ANOVA is a statistical model for analyzing the differences between group means in comparison to differences within group means. ANOVA is helpful for comparing three or more groups (e.g., Treatment Group A, Treatment Group B, Control Group) on a particular dependent measure (e.g., number of days of heavy drinking) and determining whether the differences in group means reaches statistical significance. A mixed model ANOVA is used when the researcher wants to make at least one comparison between different groups and at least one comparison of repeated measures. For instance, a researcher would use a mixed model ANOVA to test differences in Treatment Group A, Treatment Group B, and the Control Condition with measurements taken before treatment and after treatment.
Associative Learning: Associative learning occurs when a person forms a new association. Sometimes we form associations between two pieces of information we take in—for instance, we associate a person’s face with his name. Other times, we form associations between our actions and outcomes. For instance, we might learn to associate eating spoiled food with becoming ill. If we have repeated experiences with an association, that association is strengthened through a process called consolidation. Eventually, the association is stored in long-term memory. Scientists believe that a part of the brain called the medial temporal lobe is essential to associative learning.
For more information, see the American Psychological Association.
Attributions: Inferences people make about the causes of behavior or events; explanations for why behaviors or events occur.
Attribution Theory: The study of how people understand and explain the causes of behavior.
Attrition Bias: Attrition is the term for when participants of a study do not finish the study. Some participants may be at higher risk than others for dropping out of a study. If members of a particular subgroup of the study population are more likely to not finish the study than others, then the study might be less likely to include data or full cases from that subgroup, and therefore might be biased against that subgroup. We refer to this bias due to different chances of dropping out as attrition bias.
Bayesian Information Criteria: A measurement of the relative goodness-of-fit of a statistical model, with stronger penalties on models that overfit or have too many variables (See AIC).
Berkson’s Bias: One type of selection bias. Research studies sampling people in treatment might find differences between treatment recipients and people not in treatment, and these differences can alter the results. For example, recovering heroin users are dispersed throughout communities and therefore difficult to find to enroll in a research study. Accessing a methadone treatment program, which treats heroin users, would yield more potential study participants in a short time. However, those receiving treatment might have more health problems or psychological disorders than participants not receiving treatment. If the study only samples treatment recipients, its results might only apply to this subset of the recovering heroin user population.
Bidis: Bidis (also spelled beedi) are tobacco cigarette hand-rolled in leaves from the Coromadel Ebony tree native to Asia. They are referred to locally as tendu leaves.
“Big Five” Personality Traits: The “Big Five” is a theory of personality. Many researchers believe that the so-called “Big Five” personality traits together describe the full range of human personality in a largely non-overlapping manner. The “Big Five” factors are extraversion (outgoing/energetic vs. solitary/reserved), conscientiousness (efficient/organized vs. easy-going/careless), agreeableness (friendly/compassionate vs. cold/unkind), neuroticism (sensitive/nervous vs. secure/confident), and openness to experience (inventive/curious vs. consistent/cautious). Twin studies suggest that the Big Five result from a mixture of genetics and environmental factors.
Binge Drinking: According to the National Institute of Health, binge drinking is “a pattern of heavy drinking that occurs during an extended period of time set aside for drinking. Has been described as 5/4 binge drinking: five or more drinks in a row on a single occasion for a man or four or more drinks for a woman”.
Accessed September 12, 2008 from http://science.education.nih.gov/supplements/nih3/alcohol/other/glossary.htm.
Bivariate Association: A bivariate assoication occurs when two variables share a relationship such that when one changes, we expect the other to change.
Adapted from Healey, Joseph (2012). Statistics: A Tool for Social Research. 9th edition.
Blood Alcohol Content: A metric of alcohol intoxication, often used for medical and legal purposes.
Bogus Pipeline: An experimental paradigm where researchers claim to have the ability to measure accurately or to confirm hidden information about the participants. This approach is based on the idea that participants who believe researchers will be able to expose any untruthful responses are more likely to be truthful in their answers and open about socially undesirable attitudes.
Bootstrapping: Bootstrapping is the process of drawing samples, usually the same size as the original data set, with replacement (called “resamples”) from a data set. Statisticians often perform some sort of operation on each resample (e.g., take the mean of each resample), and then use the results to draw conclusions about the original data set or the initial population the sample was drawn from (e.g., use the means of the resamples to generate a confidence interval for the mean of the population). Bootstrap procedures tend to involve hundreds if not thousands of resamples.
Bradford Hill’s (1965) Criteria for Causality: In most studies, researchers are unable to conclude that a change in one variable caused a change in another variable. However, some types of evidence do support a causal relationship between two variables. Alone, none of the following criteria are evidence of causality. Taken together, they serve as a gauge for the likelihood of a causal relationship:
- Strength– The greater the degree of association between one event and another, the greater likelihood that there is a causal relationship.
- Consistency– If the findings are largely consistent with the results of similar research, there is more evidence of causality.
- Specificity– Researchers must be very specific when claiming what conditions produced the effect, or they may otherwise falsely generalize findings to conditions that do not produce the effect.
- Temporality– One event must have taken place before the other to claim that the first was the cause. Longitudinal studies are helpful in establishing temporality because they follow the same participants over time, taking measures of a potential cause and later taking measures of a potential effect. For example, someone must have started smoking before developing of lung cancer in order for smoking to cause lung cancer.
- Biological Gradient– The presumed effect should occur more often when greater exposed to the cause. For example, people who have more exposure to cigarette smoking are more likely to develop lung cancer.
- Plausibility– If a logical and plausible explanation for why the first event caused the second event exists, it provides more support for causality. This is largely dependent on the scientific knowledge available on the subject. For instance, it is plausible that smoking causes lung cancer because cigarettes contain harmful chemicals.
- Coherence– Cause and effect relationships discovered in the laboratory should also naturally occur without scientific interference.
- Experiment– When researchers manipulate one variable and control all of the other variables that could plausibly exert an influence, they have solid evidence of causality.
- Analogy– When one variable appears to be causing the effect, a researcher should investigate and rule out other possible explanations.
Bradford Hill, A. (1965). The environment and disease: Association or causation, Proceedings of the Royal Society of Medicine, 295-300.
Breathalyzer: A device that measures a person’s blood alcohol content from their breath.
Buprenorphine: A medication prescribed or dispensed in doctor’s offices to help people reduce their use of opioids through by reducing the symptoms of withdrawal and cravings. It is often prescribed as part of a comprehensive treatment plan, including individual and/or group psychotherapy.
”Buprenorphine.” Substance Abuse and Mental Health Services Administration. May 31, 2016. Accessed November 02, 2017. https://www.samhsa.gov/medication-assisted-treatment/treatment/buprenorphine.
CAGE: The CAGE assesses alcohol problems using four questions. The four questions form an acronym of the assessment’s name:
Cut down: Have you ever felt you ought to cut down on your drinking?
Annoyed: Have people annoyed you by criticizing your drinking?
Guilty: Have you ever felt bad or guilty about your drinking?
Eye-opener: Have you ever had a drink first thing in the morning (eye-opener) to steady your hands?
Ewing, J. A. (1984). Detecting alcoholism: The CAGE questionnaire. Journal of the American Medical Association, 252(14), 1905-1907.
Cambridge Gamble Task: Participants have to choose which color box conceals a token. The proportion of boxes that are blue or red varies each trial. Participants also wager on their decisions.
CANTAB Spatial Working Memory Test: Participants open boxes on a computer screen to try to locate tokens. Tokens can appear in empty boxes that have been previously opened, but cannot reappear in boxes in which a token has already been found.
Case Control Study: The epidemiological method of investigation of a condition of interest that compares the history of exposure to specified risks among cases to exposure among persons who resemble the cases in other respects but do not have the condition of interest, the controls. This method is particularly useful in the study of rare conditions.
Causality: Causality when one event causes another event, though it is difficult to prove. Researchers should be cautious making claims about causality and readers should be cautious interpreting claims of causality, as it cannot always be determined with absolute certainty that one event caused an event. If the variables are measured at the same time, as in correlational studies, a third, unmeasured variable could have produced both the “cause” and the “effect;” or, the causal relationship could actually go in reverse—the “effect” might have produced the “cause.” However, when many of Bradford Hill’s (1965) Criteria for Causality are met, this provides greater support for a causal relationship between two events.
Censoring: We are accustomed to use “censored” to indicate that something has been withheld for some reason. The term is used in working with time-related data such as survival analysis to indicate missing observations rather than withheld information. Although the participant in a study is still available to contribute information. the time when an event occurred might be missing for basically two reasons. First, the data collection ended at a certain point in time. The analysis can estimate what contributed to the event occurring up to that time, but only for those cases in which the event occurred. For the cases in which the event had not occurred by the end of the study period, there is no information about what might contribute to the event at some later date. These data are “censored” or “missing” because the study ended. This type of study is usually referred to as including “suspended” data.
A second common type of censored data is the result of measuring the presence of an event not continually but at some interval. Studies often obtain information over time by repeating measures at intervals. If the event is observed at a scheduled point in time it may not be possible to determine when since the previous measurement period the event occurred. The information about exactly when the event occurred is missing and usually referred to as “interval censored” data.
Chi-Square Test: A statistical test that is used to determine the probability that results observed have been obtained by chance. Commonly, a chi-square test is used to determine whether the frequency of an observation is statistically different between a number of mutually-exclusive groups. For example, imagine if you wanted to see whether there is a difference in the proportion of students hospitalized in the past year between two different colleges. At College A, 47% of students have been hospitalized in the last year, compared to 36% at College B. A chi-square test will tell you whether the difference between these two frequencies is statistically significant.
Clinical Global Impression-Severity Scale (CGI-S): A 7-item scale used to assess the severity of pathological gambling (PG) symptoms.
Guy, W. ECDEU assessment manual for psychopharmacology. US Department of Health, Education and Welfare Publication (ADM) 76-338. Rockville, MD, National Institute of Mental Health, 1976.
Classical Conditioning: Occurs when an individual learns to associate a neutral stimulus, such as the sound of a tone, with a reflexive response, such as an eyeblink, by way of a third stimulus. For example, in the eyeblink classical conditioning task, the researchers repeatedly pair a tone (the Conditioned Stimulus) with a mild puff of air to the eye (the Unconditioned Stimulus). The air puff naturally produces an eyeblink (Unconditioned Response). Over time, participants learn to associate the tone with blinking and will blink after hearing the tone. In other words, they exhibit a Conditioned Response (CR). Researchers often measure CRs in order to understand whether a study participant has demonstrated classical conditioning, a form of associative learning. Classical conditioning is sometimes called Pavlovian conditioning. Pavlov made a famous observation that after repeatedly hearing a bell sound before getting food, dogs will begin to salivate simply upon hearing the bell.
Classification and Regression Trees (CART): CART is a statistical methodology for developing decision trees for separating a population into subgroups and/or classifying individuals.
Clinical Significance vs. Statistical Significance: Statistical significance means that there are differences between groups that are large enough to rule out chance occurrence. However, in absolute terms, the basic proportions and differences might be small. In this case, the difference is not clinically significant. For example, people who received a gambling intervention scored significantly lower on a measure of gambling problems than people who did not receive the intervention. However, if the difference in scores was only one point out of 100, then the treatment would not have a clinically significant impact on the participants.
Closed (Close-Ended) Question: A type of question asking the respondent to choose an answer from a specified list.
Cluster Analysis: Cluster analysis is an exploratory technique that groups cases (in many instances, participants) together based on similar characteristics. The technique includes information about the optimal number of clusters within a sample and the similarity within and between clusters.
Cluster Sampling: The use of random sampling methods to select clusters in two or more stages, for example a sample of individuals from districts, counties, or households, from a UNIVERSE of all districts, counties, or households that are available for study.
Cognitive Behavioral Therapy (CBT): A type of psychotherapeutic approach addressing maladaptive emotions, behaviors, and cognitive processes. The goal is to systematically challenge the dysfunctional emotions, behaviors, and cognitions while learning coping strategies which will be used later in life even following the conclusion of therapy. This technique is used for a number of mental health disorders such as depression, anxiety, substance abuse.
Cognitive Disinhibition: A personality trait characterized by impulsive behavior, sensation seeking, and disregard for consequences. Cognitive disinhibition is independent of behavioral disinhibition – the ability to inhibit responses.
Cognitive Epidemiology: A field of research that connects people’s cognitive functioning to their morbidity and mortality.
Cognitive Restructuring: A method of treatment in which participants are taught to recognize and correct distorted cognitions that contribute to their problem.
Cohen’s Kappa Coefficient: A statistical measure of agreement between raters or on a measure conducted at different points in time. The values indicate < 0 no agreement; 0–.20 – slight, .21–.40 – fair, .41–.60 – moderate, .61–.80 – substantial, and .81–1 – almost perfect agreement.
Comorbidity/Co-Occurring Conditions: The simultaneous occurrence of two or more diseases/disorders in a single individual.
Confederate: An actor who, unbeknownst to research participants, is working on behalf of experimenters to fulfill a part of the experimental design.
Confidence Interval: A confidence interval is a numerical range that the researcher believes covers the true value of the population parameter. Most commonly, researchers report a 95% confidence interval (95% CI). This means that if we were to repeatedly make new point estimates using the same procedure (i.e., by drawing new samples, conducting surveys, and calculating point estimates and confidence intervals), the confidence intervals would contain the true value within the population 95% of the time. The CI is often reported in square brackets following the point estimate. There are some short-hands for interpreting CIs. For logistic regression, confidence intervals that do not cross 1 (e.g., 1.50 to 5.53) imply that there is a statistically significant difference in the odds of a given event, compared to a reference group. In addition, the larger the confidence interval for a particular estimate, the more caution is required in concluding that the point estimate represents the true population parameter.
Confirmation Bias: The tendency to seek, interpret, and create information that verifies existing beliefs.
Confirmatory Factor Analysis: A type of factor analysis where the researcher begins with a preconceived notion or hypothesis of which factors influence which variables and then measures how well the results and data fit the hypothesis.
Confounding: This occurs when the apparent relationship between a predictor and outcome is influenced by other factors, some of which might be unmeasured or unrealized. Scientists can use study designs and analytic strategies to control for confounding in their research.
Content Analysis: Content analysis is a research technique that provides replicable and valid inferences into the use of certain words, themes, phrases, or concepts in a given text that can include newspapers, film, TV, websites, and participant responses to open-ended questions.
Control: Researchers design experiments to eliminate (control for) the effect of non-experimental variables on the results. For example, a study may compare the outcomes of two groups that differ only because one received the experimental condition and the other did not (the control group). Medication trials are often “placebo controlled” by using a control group that is treated similarly in all ways except they receive a non-active medication (placebo) instead of the active medication being studied.
Convenience Sampling: A study design where those administering the survey passively advertise it and depend on participants to come to them. The primary issue with convenience sampling is that the results tend to be biased towards motivated respondents and strong opinions.
Correlation: Pearson’s correlation statistic is used to test the linear relationship between two numerical variables. The correlation is always between -1 and 1. A correlation of -1 implies a strict exact negative relationship between the two variables. A correlation of 0 implies that there is no linear relationship between the two variables. A correlation of 1 implies a strict, exact positive relationship between the two variables. For categorical or ordinal variables, statisticians often use other types of correlation, such as Spearman’s rho.
Cotinine: A nicotine metabolite. Cotinine levels are an indication of exposure to tobacco smoke.
Counterbalanced Design: Counterbalancing is a method for controlling order effects in a repeated measures (or within-subjects) design (i.e., a design in which the same participants are exposed to multiple experimental conditions). In a counterbalanced design, different participants receive are exposed to the same experimental conditions but in different orders. For example, one group of participants might complete a task under a placebo condition and then under an alcohol condition. Another group might complete the task first under an alcohol condition and then under a placebo condition.
Cross-Sectional Study Design: A survey of a population used to measure both disease risk factors and disease outcomes at the same moment in time. Cross-sectional research is limited in that they cannot measure cause and effect relationships.
D Score: The difference between means.
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Hillsdale, NJ: Lawrence Earlbaum Associates.
DeFries-Fulker Regression Model: Used to estimate genetic heritability of and shared environmental influences on a behavior. The model uses one sibling’s behavior (S1) and the degree of genetic relation between siblings to predict the other sibling’s behavior (S2). The unstandardized coefficient associated with S1 provides the amount of variance in S2 accounted for by shared environment, and the unstandardized coefficient associated with the interaction between S1 and sibling relationship provides the amount of variance in S2 accounted for by heritability.
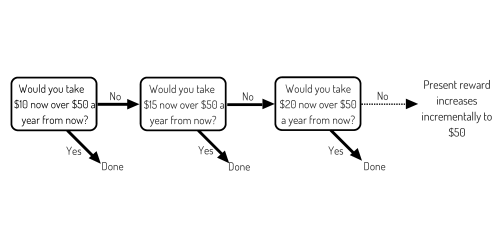
Delay Discounting Task: A research method for determining how individuals perceive the relative value of gains and losses in the present and gains and losses in the future. This is done by repeatedly offering individuals a choice between a gain (or loss) in the present and a gain (or loss) in the future. The researcher manipulates the comparisons, keeping one choice fixed (e.g., the present gain) and incrementally changing the amount or value of the other. When the individual switches their choice from present to future or vice versa, the researcher can infer something about the individual’s subjective value of present and future rewards. The graphic below illustrates an example of a delay discounting task.
Delphi Method: A systematic process by which a panel of experts answer questionnaires about a topic, the responses are analyzed by an independent source and the results given back to panelists. The panelists answer the questionnaire again taking into consideration the responses of the panel. The process repeats until the panel comes to consensus on the topic.
Deviant: Behaviors that run contrary to social norms (e.g., criminal activity, skipping school)
Difference in differences analysis: Difference in differences analysis is a statistical technique used to apply an experimental research design to observational data to simulate a “natural experiment.” Researchers calculate estimates of the effects of the explanatory (i.e., treatment) variable on a dependent (i.e., response) variable by comparing the change over time in the treatment group with the change over time in the control group. This approach can be applied to study the effects of a policy change (i.e., the treatment), such as state-level changes in marijuana laws, on a dependent variable, such as state-level rates of marijuana use. Researchers must use longitudinal data with two or more time points to successfully conduct a difference in differences analysis.
Digit Span Task: Participants are asked to recall a list of digits in order, either as presented (forward), or backward.
Diverting: People who divert medication take pharmaceuticals without a documented prescription. These people commonly receive medication from friends and family members with a prescription, purchase it on the street, or find some other outlet.
Dissociation: Dissociation refers to a state of feeling detached or removed from one’s surroundings. Dissociation can take many different forms, from daydreaming to believing the world is unreal to severe psychological disorders.
Distal Risk Factors: Distal risk factors are underlying, long-term risk factors that could make a person vulnerable to a particular health condition.
Dizygotic: Derived from two separately fertilized eggs.
Doctor Shopping: People who doctor shop have multiple clinicians who prescribe controlled substances for them. Often each clinician is unaware that their patient receives additional prescriptions from other clinicians.
Dopamine Agonist: A chemical that activates dopamine receptors in the brain. Dopamine is a common neurotransmitter that is associated with reward, motivation, and movement.
Dorsolateral: Of, relating to, or involving both the back and the sides.
Double-Blind: Neither researcher nor participant know experimental condition.
DSM-5: The Diagnostic and Statistical Manual of Mental Disorders, Fifth Edition. This handbook aims to systematize and standardize the definitions of mental disorders. Developed by the American Psychiatric Association, the DSM is the most authoritative standard for the psychiatric diagnoses in the United States.
Dysthymia: A mood disorder characterized by long-term depression.
Ecological Fallacy: Using group level data (e.g., national rate of drug abuse) to make inferences about individuals when they do not possess those characteristics as individuals.
Ecological Momentary Assessment: A technique used to gather data on momentary states of individuals who are in their “real-world” environments at the time of assessment, often using easily transportable tools such as handheld computers or mobile phones. Because assessments are completed as psychological states or behaviors occur, rather than at some later point, there is less potential for recall biases.
Stone, A. A., Shiffman, S. S., & DeVries, M. W. (1999). Ecological momentary assessment. In D. Kahneman, E. Diener, & N. Schwartz (Eds.), Well-being: The foundations of hedonic psychology (pp. 26–39). New York, NY: Russell Sage Foundation.
Effect Size: The magnitude of an experimental effect, often calculated as the mean difference between two groups divided by the standard deviation of the difference. Unlike statistical significance, effect size is not dependent on sample size. Effect size is important to consider because statistically significant effects might not be practically or clinically meaningful (for example, because they were derived from very large samples), and effects that are not statically significant might be still be strong enough to be practically or clinically meaningful.
Effectiveness: The extent to which a treatment for a disorder works for patients in every-day contexts, such as outpatient clinics or hospitals. Not to be confused with efficacy.
Efficacy: The extent to which a treatment for a disorder works within a controlled environment, such as in the context of a study or experiment. Not to be confused with effectiveness.
Ego-Defensive Bias: The tendency to take more credit for success or good behavior than for failure or bad behavior.
Electronic Cigarette: An electronic cigarette (e-cigarette) is a battery powered device that vaporizes nicotine with water vapor for inhalation.
Enzyme: Any of numerous complex proteins that are produced by living cells and catalyze specific biochemical reactions.
Epidemiological Study: Research on the incidence, distribution, control, and/or cause of diseases, health trends, or disorders by studying populations.
Excitatory: Promoting the action of (an)other neuron(s); increasing the probability that a postsynaptic neuron will fire.
Executive Function: A collection of brain processes that control and regulate other abilities and behaviors and make goal-directed behavior possible.
Experiment: A type of study where the researcher randomly assigns participants to different groups, varies the conditions that each group experiences, and controls for possible sources of bias. In contrast to every other kind of study design, true experiments allow researchers to draw conclusions about what causes what. When a researcher is unable to randomly assign participants to specific groups (for example, in a study comparing students who smoke to students who do not smoke), the study is better described as quasi-experimental.
Exploratory Factor Analysis: A type of factor analysis where the researcher makes no a priori assumptions about the structure of the relationships between the observed variables.
External Validity: The degree of generalizability of the obtained results beyond the given setting and a sample group of participants. Experiments are said to possess external validity if their results may be used to make predictions about entire population in different circumstances. Researchers can increase external validity by selecting a representable sample of participants and creating conditions that are similar to real life. Frequently, strict control for confounding variables (i.e., high internal validity) prevents achieving high external validity due to creating too artificial a lab setting.
fMRI (Functional Magnetic Resonance Imaging): An imaging of the brain using MRI technology, fMRI scan uses radio waves and a strong magnetic field to measure the levels of blood in specific parts of the brain.
Factor Analysis: Data reduction technique that analyzes the relationships among a set of variables in order to identify clusters that vary together as a group. Each cluster consists of several measures of the same underlying dimension (or factor) and the common information can be largely or entirely explained by a single composite of the several variables in the cluster.
False Consensus Effect: The tendency to overestimate the consensus of our own opinions, attributes, and behaviors.
Fixed-Effect: A statistical technique that allows researchers to control for observed and unobserved characteristics of the unit of analysis (e.g., a person, organization, etc.) that doesn’t change over time.
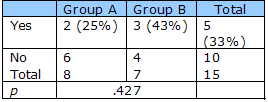
Fisher’s Exact Test: This statistical test measures the likelihood that the proportion of cases distributed across two cells (e.g., Yes or No) in two independent groups (A and B) could have happened by chance if the two groups were sampled from the same population. Fisher’s exact test computes the probability (p) of obtaining the observed arrangement of “yeses” as compared to obtaining each of all the possible arrangements of “yeses” in the two groups. In the case below (see figure 1), the probability of observing a difference in proportions as great or greater than 2 of 8 versus 3 of 7 is .427. Fisher’s test is an “exact” test because the actual number of ways in which the “yeses” and “nos” can be arranged is an exact calculation (particularly with small samples, the most common use of the test).
Figure 1 – Fisher’s Exact Test
Fundamental Attribution Error: The tendency to focus on the role of personal causes and underestimate the impact of situations on other people’s behavior.
Gambling Disorder: A mental health diagnosis in the DSM-5 classified as a non-substance-related addictive disorder. People with gambling disorder gamble repeatedly despite experiencing a range of negative consequences caused by their gambling behavior. People with gambling disorder might experience a range of symptoms that are similar to what individuals with substance-related addictive disorders experience.
Gambling Levels: Public health systems often assign levels to phenomena of interest; For example first and second degree burns. The gambling level system is a public health tool that classifies people along a gambling involvement continuum. This continuum often begins with healthy gambling behavior that does not produce any adverse reactions. On the other end of the continuum is gambling behavior with the most serious adverse consequences.
Level 0 : People who do not gamble.
Level 1 : People who gamble with no adverse consequences.
Level 2 : People who gamble with any of a wide-range of adverse reactions or consequences that do not qualify the gambler for the most serious form of gambling disorder; level 2 gamblers represent people who may be moving in either of two directions: toward an increasingly disordered state (level 3) or toward a healthier level of gambling (level 1).
Level 3 : People who gamble with adverse consequences that are sufficiently serious and co-occurring so as to meet diagnostic criteria.
Level 4 : People who seek help for gambling problems regardless of the extent of their problems or distress
Geographic Information Systems (GIS): Geographic Information Systems (GIS) refer to software programs that create and analyze maps. ArcGIS is the most popular GIS software and it is used in research studies that examine geographic trends across different spatial units (e.g., neighborhoods, cities, states or countries).
Generalizable: Result of a study are generalizable if they can be applied to populations other than just the study sample.
Generalized Estimating Equations: Generalized estimating equations are statistical tools that allow for the prediction of an outcome based on both fixed factors and an estimation of random factors. Generalized estimating equations differ from regression in that they account partially for random variables that can affect the outcome, for example, changes in weather or mood.
Gold Standard: An independent criterion that can validate the presence or absence of a disordered state.
Group-Based Trajectory Analysis: Group-based trajectory analysis is a statistical technique for grouping individuals based on their growth, change, or evolution over time. Much like in cluster analysis, the procedure generally speaking groups individuals with similar data values or patterns together. However, instead of designating individuals to specific groups, group-based trajectory analysis gives each individual probabilities of membership in each group.
Growth Mixture Modeling: A statistical technique used to model individuals’ growth over time on a given variable or set of variables classify individuals according to those trajectories. Growth mixture modeling is one of several person-centered approaches used to understand individual trajectories. Person-centered approaches account for individual variation within samples and groups. This is in contrast to variable-centered approaches, such as regression, which highlight averages and relationships between variables.
For more information, see Jung & Wickrama (2008). An introduction to latent class growth analysis and growth mixture modeling, Social and Personality Psychology Compass, 2/1, 302-317. http://www.statmodel.com/download/JungWickramaLCGALGMM.pdf.
Hazard Rate: Formally speaking, the hazard rate is the ratio of the probability density function to the survival function. This page on Hazard Rates provides a concrete example: When you are born, you have a certain probability of dying at any age; that’s the probability density. For example, a girl born today has, say, a 1% chance of dying at 80 years. However, as she survives for a while, her probabilities of dying on any given day keep changing. For example, when she is 79 years old, she might have a 5% chance of dying at 80 years.
Hazard Ratio: Hazard ratio is an important outcome measure, often used in survival (or time-to-event) analysis. It is the ratio of the hazard rates corresponding to two conditions, such as a treated population and an untreated population. The ratio describes the relative likelihood that an outcome will occur within a given group, within a given timeframe.
Hierarchical Linear Models (HLM): Statisticians use hierarchical models when observations or participants can be partitioned into groups and also into subgroups within each group. For example, a study of college students may include students from several different schools, and then within each school, students from several different majors. Hierarchical models are used to explore possible differences within each group and subgroup, and between the groups and subgroups. Depending on the model, the coefficients (“betas”) might be used to, for example, estimate the expected values of the dependent variable for each group or subgroup, or measure the differences between one group’s trajectory of growth and another’s.
Hookah: A hookah – also known as shisha or narghila – is a waterpipe used to smoke primarily flavored tobacco, although it can be used for marijuana and other substances. A typical hookah consists of a 1-3 foot base containing the tobacco, coals, and water, as well as several hoses to inhale the smoke through. Originating from the Middle East, the hookah is becoming increasingly popular as a social smoking behavior in the United States. A typical hookah session might last an hour or even longer.
Hole Cards: In poker, cards that are dealt to a player face down. Contrast with board cards in stud poker, which are dealt face up, or community cards in hold’em poker, which are placed in the middle of the table and shared by all the players.
House Advantage: The house advantage of a gambling game is how much the player is expected to lose, expressed as a percentage of the size of the initial bet.
Humanities: Those branches of knowledge, such as philosophy, literature, and art, that are concerned with human thought and culture; the liberal arts.
The American Heritage® Dictionary of the English Language, Fourth Edition. Copyright © 2000 by Houghton Mifflin Company.
Iatrogenic: Illness resulting from a physician’s professional activity or from the activity of other health professionals.
Idiographic Approach: A method of inquiry that focuses on the individual rather than the group. It is used to gather information about the subjective experience of an individual in order to determine what makes the individual unique. By contrast, a nomothetic research approach attempts to establish general laws that are applicable across individuals. Both approaches have both strengths and weaknesses.
Illusion of Control: A belief in our ability to influence events over which we have no control.
Implicit Association Test (IAT): A computerized reaction-time task designed to measure the strength of association between target concepts (e.g., flowers and insects) and attribute concepts (e.g., pleasant and unpleasant). Participants categorize stimuli as quickly as possible by pressing a computer key. In critical blocks, participants use the same computer key to categorize both a target concept and an attribute concept. The IAT measures the milliseconds required to sort stimuli. The strength of the association between targets and attributes , operationalized as the quickness with which participants respond, is referred to as an “implicit association.” You can take a demo test online.
Imputation: A series of methods for estimating missing values in a data set. Most methods use a mathematical model and the non-missing information in the data set.
Incidence: Incidence is an important concept in public health research. It refers to the proportion of people in a population who have newly developed a given medical condition during a specified period of time.
Incident Rate Ratio: The ratio of two incidence rates. The incidence rate among the exposed proportion of the population, divided by the incidence rate in the unexposed portion of the population, gives a relative measure of the effect of a given exposure. Incident rate ratios that are close to 1.0 indicates little effect of a given exposure on health outcomes. See this definition in the Harvard Geo Coding Project glossary
Independent Samples T-Test: Procedure for testing whether one population or experimental group is significantly different from another. In this experimental design, the researcher samples from each group separately, and calculates separate summary statistics for each group. For example, to test whether experienced poker players can estimate probabilities more accurately than non-players, a researcher might gather a group of poker players and a group of non-players separately, ask everyone in both groups to estimate some probabilities, and then compare the average accuracy of the poker players to the average accuracy of the non-players.
Indirect Effect: A measure of the extent to which a given variable mediates the relationship between an initial variable and an outcome variable. Statistically, it is defined as the reduction of the effect of the initial variable on the outcome variable.
Information Sampling Test: Participants open as many boxes as they choose in a 25 box grid. Each box reveals one of two colors. Participants must decide which color is in the majority; they can make this decision at any point and receive points for correct answers. In one condition, they receive the same points regardless of how many boxes they open; in the other their points decrease the more boxes they open.
Inhibitory: Modifying, inhibiting, or suppressing the action of (an)other neuron(s); reducing the probability that a post-synaptic neuron will fire.
In Situ Hybridization: In situ hybridization is a method of locating a specific mRNA sequence by introducing its compliment into the tissue. The compliment is usually attached to a label of some sort, fluorescent or otherwise, so that when these two complimentary halves find one another and bind together, the researcher can easily locate the mRNA he or she is interested in.
Intent to Treat Analysis: A procedure in the conduct and analysis of randomized trials. All patients allocated to each arm of the treatment regimen are analyzed together as representing that treatment arm, whether or not they received or completed the prescribed regimen. Failure to follow this step defeats the main purpose of random allocation and can invalidate the results.
Inter-rater Reliability: The degree to which two independent raters agree when they are assessing the same thing by the a given set of criteria. In psychology, researchers use different types of assessments in order to evaluate a specific “object” (e.g., a participant, a type of therapy, a body of literature) using a given set of criteria (e.g., a researcher notes every time a participant nods their head). Using a single researcher (i.e., a rater) might lead to biases in judgement (e.g., different raters might consider different movements to represent a head nod). To make up for potential bias, researchers often use more than one rater to make evaluations. Inter-rater reliability is a measure of how much these two raters agree on a set of evaluations (e.g., how often the raters agree that a participant nodded their head). Inter-rater reliability is also known as concordance. Some indices of inter-rater reliability include percent agreement, Cohen’s kappa, and Fleiss’ kappa.
Interrupted Time Series Observational Studies: A study design where measures from a sample population are collected several times before and after an event.
Internal Validity: The degree of validity of causal inferences in scientific studies. Experiments are said to possess internal validity if they demonstrate a causal relation between two variables (a cause and an effect). Researchers can increase internal validity by carefully controlling for confounding variables that could provide alternative explanations for observed effects.
Internet Panel: An internet panel is a group of people who have signed up to participate in online surveys for research. Researchers use internet panels to obtain samples that have similar demographic characteristics to a particular population. For example, a researcher who wanted to learn more about the percentage of people who use marijuana in the state of Florida could use an internet panel to obtain a sample of people who live in Florida and have similar demographic characteristics to the state of Florida. Internet panels may suffer from issues related to representativeness, validity and self-report bias.
Intraclass correlation: A type of correlation used when members of a pair cannot be assigned to distinct variables. For example, data for wives and husbands could be organized by the two variables “wife data” and “husband data,” but data for two same sex siblings could not be assigned to variables in any non-arbitrary way. If a regular Pearson correlation were used in the latter case, it would change depending on which sibling was labeled sibling 1 or sibling 2. The intraclass correlation does not rely on the order of the variables, and is thus more appropriate in the latter case.
Also see this example by the University of Vermont for a good reference.
Intrinsic and Extrinsic Motivation: Ryan and Deci’s Self-Determination Theory defines intrinsic motivation as motivation that is generated internally, such as interest or curiosity; and extrinsic motivation as motivation that is generated externally by an outcome outside of the activity itself, such as a money reward or an evaluation.
Intrinsic and Extrinsic Goals: Intrinsic goals are goals that are self-satisfying independent of external factors. Extrinsic goals are goals that focus on external consequences outside of the task alone.
Deci, E. L. (1971). Effects of externally mediated rewards on intrinsic motivation. Journal of Personality and Social Psychology, 18(1), 105-115.
Vansteenkiste, M., Lens, W., & Deci, E. L. (2006). Intrinsic versus extrinsic goal contents in Self-Determination Theory: Another look at the quality of academic motivation. Educational Psychologist, 41(1), 19-31.
Also read about Self-Determination Theory to learn more.
Iowa Gambling Task (IGT): A task designed to simulate decision making, particularly the kind of decision-making often involved in gambling. In the task, participants are presented with four decks of cards. (These might be actual decks of cards, or virtual cards on a computer screen.) The participant is told that the game requires them to choose cards, one at a time, from any of the four decks. The participant receives a monetary reward after turning over each card. The reward amount varies from card to card. Some cards, however, come with both a reward and a penalty. The decks differ in how much profit they ultimately provide. Some decks (i.e., “disadvantageous decks”) are programmed such that they pay larger rewards throughout the entire task and, over time, produce larger and larger penalties. Other decks (i.e., “advantageous decks”) pay smaller rewards throughout the task but also produce smaller penalties. Over time, it becomes more profitable to select from the latter decks. Researchers typically measure how long it takes participants to learn to choose from the advantageous decks. People with certain types of mental health conditions or brain abnormalities tend to show poor performance on this task, indicating a reduced sensitivity to future consequences.
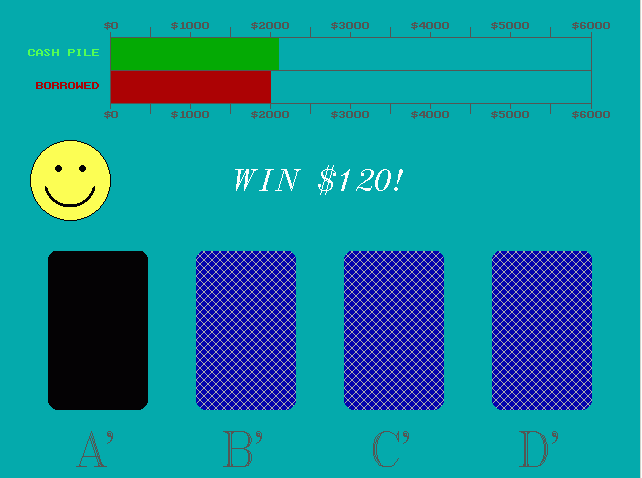
Screenshot of the Iowa Gambling Task.
Bechara, A., Damásio, A. R., Damásio, H., Anderson, S. W. (1994). Insensitivity to future consequences following damage to human prefrontal cortex. Cognition 50 (1-3): 7–15.
Item Response Theory : The study of test and item scores based on assumptions concerning the mathematical relationship between abilities (or other hypothesized traits) and item responses. Other names and subsets include Item Characteristic Curve Theory, Latent Trait Theory, Rasch Model, 2PL Model, 3PL Model, and The Birnbaum Model.
Baker, Frank (2001). The Basics of Item Response Theory. ERIC Clearinghouse on Assessment and Evaluation, University of Maryland, College Park, MD.
Krusal Wallis test: The Kruskal Wallis test is the non parametric alternative to the One Way ANOVA. Non parametric means that the test doesn’t assume your data comes from a particular distribution. The H test is used when the assumptions for ANOVA aren’t met (like the assumption of normality). It is sometimes called the one-way ANOVA on ranks, as the ranks of the data values are used in the test rather than the actual data points. Definition from https://www.statisticshowto.com/kruskal-wallis/.
Latent Class Analysis (LCA): A statistical method for identifying unmeasured class membership among subjects using categorical and/or continuous observed variables.
Latent construct: Mechanism or attribute that is not directly measured by any variable in a data set, but might be the underlying concept or domain that multiple variables attempt to measure. For example, a data set might contain information on whether or not individuals believe in lucky clothing, use horoscopes to classify days as favorable or unfavorable for gambling or taking risks, or believe that particular numbers are lucky or unlucky. Susceptibility to superstitious beliefs is a latent construct that might underlie those three variables.
Latent growth modeling: Researchers use latent growth models to describe how individuals’ attributes (e.g., weight, level of fitness) are related to their change on an outcome variable (“growth”; e.g. how fast they can run a mile) that is measured repeatedly over time. In these models, each individual has his or her own growth curve or trajectory. For example, imagine you are conducting a study that involves having participants run a mile once a week for two months. You may hypothesize that individuals who have a high level of fitness at the beginning of the study can already run quickly and will only improve their time by a matter of seconds, whereas individuals who enter the study with a low level of fitness may end up reducing their time by several minutes by the end of the study as their fitness increases. Furthermore, you may hypothesize that participants that weighed more at the beginning of the study may lose weight throughout the course of the study and as a result will run faster, whereas participants who did not weigh much at the beginning of the study will not lose much weight, which subsequently will not impact their run time. You can then test this model that you have created to see if the patterns you hypothesized are reflected in the data that you collected from your study.
Learned helplessness: The phenomenon in which experience with an uncontrollable event creates passive behavior toward a subsequent threat to well-being.
Likert Scale: A survey item where the participant is shown a statement and then asked about the extent to which the he or she disagrees or agrees with the statement. There is a short, ordered list of between 3 and 7 possible responses, ranging from strong disagreement to strong agreement. For example, there may be five possible answers: strongly disapprove, disapprove, neutral, approve, strongly approve. Researchers adapt this style for questions about a range of concepts.
Linear Regression: A type of regression analysis whereby the researcher attempts to model the relationship between a dependent variable (y) and independent variable(s) (x) fitting a linear equation to the data. Linear Regression estimates the coefficients of the linear equation that best predict the value of the dependent variable. For example, a researcher might try to predict a salesperson’s total yearly sales (the dependent variable) from independent variables such as age, education, and years of experience.
Logarithmic transformation: The process of transforming data to the logarithmic equivalent. Often applied to convert data that is not normally distributed to a more normal distribution.
Log-Likelihood Statistic: Measurement based on a statistical model’s structure used to assess the explanatory strength of said model for a given data set.
Logistic Regression: A statistical method used to see if a set of variables can predict a dichotomous outcome – that is, an outcome that only has two options (e.g., true or not true; winning or losing, getting a disease or not getting a disease). For example, a study may follow a group of children through adulthood to see if aspects of their upbringing (e.g., socioeconomic status, attachment to parents, school achievement) predict whether or not they receive a diagnosis of depression in their lifetime. Here, the outcome is dichotomous because a participant can either have had a diagnosis or not had a diagnosis – there is no possibility for half a diagnosis. Logistic regression coefficients can be used to estimate odds ratios for each of the independent variables in the model. Logistic regression is similar to linear regression, but in linear regression the outcome is scalar (e.g., height, weight, number of years of education, annual salary, etc.).
Cited from the SPSS Help Library.
Long Term Potentiation (LTP): LTP is a commonly used measure of addiction in neuroscience. Neurons in the nucleus accumbens (part of the reward center) of the brain are stimulated with an electrode and the responses are recorded. Substances like cocaine can cause neurons to respond more strongly to an identical stimulus than untreated neurons (potentiation). This response can be maintained for relatively long periods, even after the withdrawal of the substance (long term).
Longitudinal Study: A research design where researchers collect data multiple times from the same group of participants over a set period of time, often spanning months or years. For example, researchers interested in the way people develop addiction in their twenties might recruit and survey a group of graduating high school students. They could then survey these students yearly for the next ten-years to measure how their substance use behaviors have changed.
Loss Aversion: The tendency for people to assign greater weight to losses than gains when considering a risky proposition.
Losses disguised as wins (LDWs): A term describing the result of playing a slot machine in which the player wins money, but less money than they bet on that slot machine spin.
Magical Thinking: Belief in causal forces beyond the scope of physical reality (e.g., luck).
MANOVA: A Multivariate Analysis of Variance compares two or more groups to test for differences between the means of two or more outcome variables. For example, a researcher might wish to compare people with Alcohol Use Disorder to people with Gambling Disorder and people with Tobacco Use Disorder on their working memory and cognitive control. A MANOVA will indicate whether any of the three groups differ in their average working memory or cognitive control scores.
Matched Pairs T-Test: Procedure for testing whether one population or experimental group is significantly different from another. In this experimental design, members of one group are paired with similar members from another. For example, to test whether drinking a sports drink helps athletes recover faster than drinking water, a researcher might match each participant with another with the same gender and similar height and weight, and then give one of them the sports drink and the other water.
McNemar Test: A statistical test that assesses differences on nominal data outcomes (i.e., data that fits into named categories, such as gender or eye color) between two different groups of subjects across two different time-points. For example, imagine if you wanted to study whether eating oily food was related to acne. You recruit one group of participants that already has acne, and one group that does not. After both groups spend a week eating oily foods, you see how many people in each group now has acne (see figure). A McNemar test will help you determine whether end-of week acne status changes (i.e., going from having acne to not having acne or going from not having acne to having acne) are statistically significant (that is, not due to chance).
Mean: One of several statistics that describe the central tendency in a group. Other measures of central tendency include the median and the mode. The mean is simply the average of all the measures; the average is the sum of all measures divided by the number of these measures. The presence of a few extreme values can result in a mean that is not a good description of the central tendency of the group as a whole.
Median: One of several statistics that describe the central tendency in a group. The median is the middle value of all measures in a group. Researchers can create a median split by dividing participants into two groups: one group with higher values will be above the middle value, and one group with lower values will be below the middle value. This procedure turns a continuous variable into a categorical variable, resulting in the loss of information about graduations between participants.
Mediation Analysis: A type of statistical analysis that researchers use to test for possible mediators. In statistics, a mediator is a variable that helps explain a cause-and-effect relationship. For example, a dietitian might teach clients how to avoid processed foods in the hopes that this intervention will improve her clients’ health. One potential mediator is a decrease in the amount of added sugar each client eats in a given day; it helps explain how the dietitian’s intervention improves her clients’ health.
Mediational Pathway: The path of an effect from a predictor (independent variable) through mediating variable(s) to a final outcome (dependent variable).
Mediator: In statistics, a mediator is a variable that helps explain a cause-and-effect relationship. For example, a dietitian might teach clients how to avoid processed foods in the hopes that this intervention will improve her clients’ health. One potential mediator is a decrease in the amount of added sugar each client eats in a given day; it helps explain how the dietitian’s intervention improves her clients’ health.
Meta-Analysis: A statistical synthesis of data from separate but similar (i.e., comparable) studies, leading to a quantitative summary of pooled results.
Middle Frontal, Inferior Frontal, Orbital Gyrus: Areas of the frontal lobe of the brain where decision making is thought to be localized.
Missing At Random: Sometimes a data set is incomplete or contains missing values. These missing values are missing completely at random (MCAR) if whether or not a value or data point is missing is independent of the underlying value itself or to any variable in the study. The missing values are missing at random (MAR) if which values are missing can be accounted for using the variables for which the data set contains complete information. Missing data is that not MCAR or MAR is considered missing not at random (MNAR). MCAR and MAR are often considered assumptions that cannot be verified statistically.
Mode: One of several statistics that describe the central tendency in a group. Other measures of central tendency include the mean and the median. The mode is the most frequent value observed in the group. Generally, the mode is used to describe the group tendency when there are only a few possible values.
Moderator: Moderation is when a variable is not necessary in order for the predictor (i.e., the independent variable) to lead to the outcome (i.e., the dependent variable), but the presence of this variable changes the quality of the outcome. For example, how much gasoline I put in my car predicts how far I can drive it. If I pour sugar into my gas tank, my car will run poorly and I might not make it to my destination. On the other hand, if I pour fuel injector into my gas tank, my car might run better and I might make it to my destination without any issues. Since neither sugar nor fuel injector are necessary components in order for me to use gas to drive to my destination, sugar and fuel injector can be said to moderate my ability to drive when I fuel up my car.
Monozygotic: Derived from a single fertilized ovum or embryonic cell mass.
Motivational Enhancement Therapy (MET): MET involves steering the patient toward finding his or her own internal motivations for fighting addiction.
Motivational Interviewing (MI): MI underscores personal motivations and benefits for change. It helps to establish a commitment to reduce or stop problem behavior and promotes the participant’s self-efficacy.
Multi-Level Models: Multi-level models, also known as mixed-effects models, are mathematical/statistical models used to analyze nested or hierarchical data.
An example of how multi-level models can be applied might be a study of how patient (level-1) and doctor (level-2) characteristics influence the amount of pain that patients experience while they recover from surgery. The hospital has 100 patients and 10 doctors. Each doctor is in charge of caring for 10 patients. Specifically, the researchers are trying to find out how much a patient’s pain during recovery can be attributed to the patient’s qualities or their doctor’s qualities.
Some of the variation in the amount of pain that the patients are experiencing will be due to the individual qualities of the individual patient – some patients are simply more sensitive to pain than others. However, some doctors are better at managing patients’ pain than others. If a doctor is very responsive to the needs of their patient, then even a very sensitive patient will experience less pain under their care than a pain-tolerant patient would with a doctor who ignores their needs. A multi-level model allows the researchers to account for the effects each doctor might have on their set of patients and the effects of each individual patient’s pain sensitivity. The multi-level model might show that 20% of a patient’s pain can be attributed to the patient’s pain sensitivities and reactions, but 80% can be attributed to their doctors’ recommendations and actions.
Multi-level models can also be used to estimate effects with multiple time periods (level-1) nested within individuals (level-2). An example of this could be a study examining how experiences of pain change over time as a patient recovers from surgery. In this example, repeated pain measurements are the lower level, whereas the individual patient is the second level. Researchers can then figure out how much of an experience of pain can be attributed to the amount of time that has passed since the surgery, and how much is attributed to the individual patient’s pain sensitivity and progression through recovery.
Multistage Sampling: A form of cluster sampling that selects among clusters defined at each stage. Rather than sampling from within all members making up a cluster, only some members of the cluster are selected at each stage. For example, a cluster sampling of households in a city is facilitated by sampling among households only in selected city blocks that are in selected postal areas that are in selected voting districts.
Naloxone: A medication used to reverse the toxic effects of opioid overdose, also known as Narcan.
“Naloxone.” Substance Abuse and Mental Health Services Administration. March 03, 2016. Accessed November 02, 2017. https://www.samhsa.gov/medication-assisted-treatment/treatment/naloxone.
Naltrexone: A prescription medication used to treat both opioid and alcohol use disorders by blocking the euphoric and sedative effects of both opioids and alcohol. Brand names are Vivitrol and Revia.
”Naltrexone.” Substance Abuse and Mental Health Services Administration. September 12, 2016. Accessed November 02, 2017. https://www.samhsa.gov/medication-assisted-treatment/treatment/naltrexone.
Natural Laboratory: A type of experiment where researchers conduct research under conditions as close to the real world as possible. For example, natural laboratory research is taking place when a researcher observers how gamblers use slot machines in an actively operating casino.
Negative Reinforcement Expectancies: The removal of a negative state that results in the increased likelihood of the previous behavior.
Negative Association: Two numerical variables are negatively correlated if an increase in one is usually associated with a decrease in the other. For example, the value of a car is negatively correlated with the number of miles on it.
Nested Data Structure: In a nested data structure, levels of one factor are completely subsumed or nested inside the levels of another. For example, consider a survey of elementary school students in a district with multiple elementary schools. If we record the students’ schools and homerooms, then the variable “homeroom” will be nested within the variable “school”.
Neurotransmitter: A chemical in the body which moves between neurons and communicates chemical messages such as pain, pleasure, emotion, and touch sensation. Some common neurotransmitters are serotonin, dopamine, and norepinephrine.
Nomothetic Approach: A nomothetic research approach attempts to establish general laws that are applicable across individuals. By contrast, an idiographic approach is a method of inquiry that focuses on the individual rather than the group. It is used to gather information about the subjective experience of an individual in order to determine what makes the individual unique. Both approaches have both strengths and weaknesses.
Nonlinear Regression: A method of finding a nonlinear model of the relationship between the dependent variable and a set of independent variables. Unlike traditional linear regression, which is restricted to estimating linear models, nonlinear regression can estimate models with arbitrary relationships between independent and dependent variables. This is accomplished using iterative estimation algorithms.
Non-Response Bias : Bias due to a sample being insufficiently random. This can happen when those who respond to a survey differ in an important way from those who do not respond.
Normal Distribution: A continuous probability distribution, which appears bell shaped, is symmetrical about the mean and has the most probable scores concentrated around the mean. Often times when we speak of the normal distribution we use as an example the Standard Normal Distribution, which has a mean of 0 and variance of 1. Also called Gaussian Distribution.
Nucleus Accumbens: Area of the brain’s reward pathway associated with feelings of pleasure.
H0: Null Hypothesis: The purpose of most statistical tests is to determine the likelihood that the observed results could have happened by chance given the hypothesis to be tested. The “null” version of a hypothesis (usually a difference in outcome due to difference in conditions) expects no difference. If the statistical test indicates that, given the hypothesis, the observed difference was not likely to have happened by chance, we can reject the hypothesis. Rejecting the null hypothesis rejects the expectation of no effect and encourages acceptance of an effect.
Observational Studies: Studies and surveys where data is collected from participants without the researchers affecting the variables and factors directly. Observational studies are usually contrasted with experiments, where researchers assign factor levels (e.g., drug dosages) to participants.
Observer Bias: Systematic difference between a true value and that actually reported by the observer, due to a failure of the observer to measure or identify a phenomenon accurately.
Odds: The ratio of the number of specific events to the number of other events (i.e., odds = # specific / # other). The odds of an event differ from the probability of an event in that the denominator for calculating odds is the non-events and the denominator for probability is the total of all events.
Odds Ratio: An odds ratio is a measure of effect size. It indicates how likely a group is to report a specific outcome, compared to a control group. An odds ratio greater than 1 indicates the group is more likely to report that outcome, while an odds ratio less than 1 indicates the group is less likely to report the outcome. Odds ratios are typically reported with the 95% confidence interval.
For example, if the results for a study show that Group A has an odds ratio of 2.5, and Group B has an odds ratio of 0.75, then people in group A were two and a half times more likely to report the outcome, compared to the control group. Participants in group B reported the outcome 3/4 as often as those in the control group.
Open Label Investigation: An open-label trial is a type of clinical trial in which both the researchers and participants know what is being administered (e.g., treatment A versus treatment B; treatment A versus placebo). This contrasts with trials in which participants (and potentially the researchers as well) are not aware of which formulation patients are receiving.
Open (Open-Ended) Question: This type of question asks the respondent to answer in sentence or phrase form.
Optical Density: Optical density is a measure of light transmittance through a given area of a developed photo image, and can be expressed as the number of dark spots in that area. This number is usually given relative to light transmittance through other areas of the image.
Orbital: Pertaining to the region above the eyes.
P-Value: A term for the probability that an event will occur. In common research terminology, the p-value of an inferential statistic is the probability that an observed outcome—and more extreme outcomes—could have happened by chance under the null hypothesis that there was no effect. Small p-values such as five times in a hundred (p = .05) are used benchmarks to distinguish effects that could have happened by chance from effects unlikely to happen by chance.
Path Analysis: Path analysis helps researchers test the validity of predicted causal relationships between multiple variables, or “A causes B and B causes C.” It uses two types of variables: exogenous (independent) and endogenous (dependent).
For example, researchers might hypothesize that gender (exogenous) will predict education level (endogenous), which will in turn predict household income (also endogenous). Researchers can assess the strength and direction of relationships between these variables using path coefficients. Results of path analysis are usually depicted in a figure like the one found in DRAM 12(10).
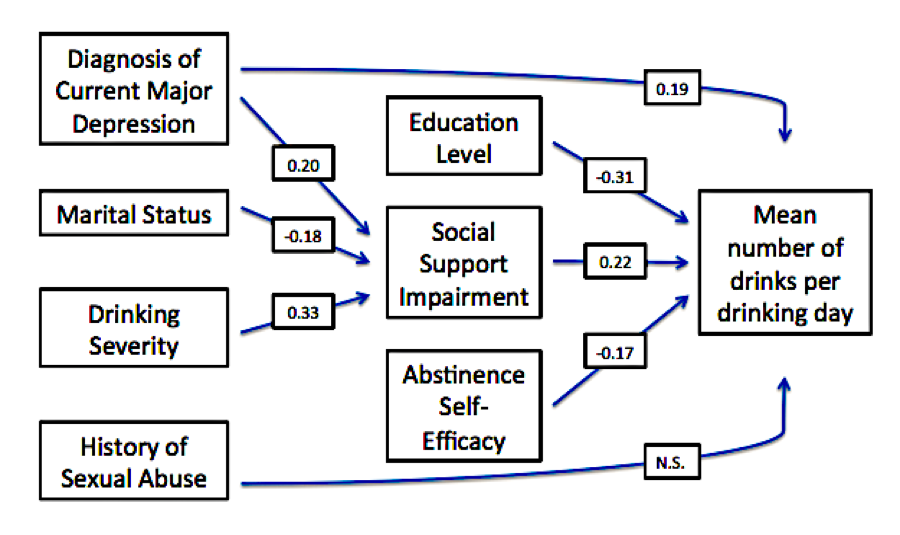
Figure adapted from:
Sugarman, D. E., Kaufman, J. S., Trucco, E. M., Brown, J. C., & Greenfield, S. F. (2014). Predictors of drinking and functional outcomes for men and women following inpatient alcohol treatment. The American Journal on Addictions / American Academy of Psychiatrists in Alcoholism and Addictions, 23(3), 226–233. http://doi.org/10.1111/j.1521-0391.2014.12098.x
PET Scan (Positron Emission Tomography): A type of imaging that uses a small amount of radioactive chemicals to help doctors see organs and tissues in action.
PGSI: See Problem Gambling Severity Index.
Phi Coefficient: A statistic used to measure the association between two binary variables. Similar to Pearson’s correlation r, a value close to -1 denotes a strong negative association, a value close to 0 denotes very little association, and a value close to +1 denote a strong positive association.
Pilot Study: A preliminary study with fewer subjects and/or simplified methods. Researchers conduct a pilot study to inform the design and conduct of a planned experiment.
Phase I : Testing the safety (toxicity), tolerability, and interactions of a drug on a small number of healthy individuals. Individuals are observed full-time to note any reactions to the drug.
Phase II : Repeating and continuing safety assessments started in Phase I and testing how well the drug works on large groups of individuals. Phase II is further separated into a and b.
Phase IIa: Specifically tests how large or small drug dosages should be.
Phase IIb: Tests the efficacy of specific doses.Phase III : Randomized controlled testing of a drug on a larger, hundreds to thousands, number of individuals (the number depends on the disease being researched) to test a drug’s safety, efficacy, and possible additional uses on a larger scale. Drugs and treatments in the Phase III stage can be sold on the market with FDA approval unless harmful effects are discovered or reported.
Phase IV : Drugs in this phase have qualified for sale on the market after all appropriate forms of testing. However, drugs in Phase IV are still tested periodically to locate any long-terms adverse effects in patients, to remain competitive with newer drugs, and to make sure that the drug does not negatively interact with other drugs, foods, or conditions.
Poisson Distribution: A measurement of the mean number of occurrences of an event at a given time or space interval. For example, a measurement of the number of customers visiting a coffee stand between 6:00AM and 7:00AM daily for 7 days.
Population: The entire collection of observations to which the study results generalize. The study sampling procedures will define the accessible study population.
Population Parameter and Point Estimate: Population parameters are characteristics of populations of interest. Researchers often want to estimate population parameters. For example, a researcher studying American teenagers might want to know the percentage of teenagers who have used marijuana in the past month. Usually, obtaining the value of the population parameter is impractical—in this case, because it would require asking every American teenager about marijuana use. Instead, researchers draw a sample from the population. They calculate a point estimate, a sample statistic calculated solely from the sample data. However, a sample almost never exactly mirrors the original population, and a point estimate is almost never the exact value of the unknown parameter. Researchers use confidence intervals to indicate how much caution is needed before concluding that the point estimate is a true reflection of the population parameter.
Positive Association: Two numerical variables are positively correlated if an increase in one is usually associated with an increase in the other. For example, monthly rent is usually positively correlated with square footage.
Post Hoc Tests: Post-hoc tests are usually focused comparisons (i.e., comparing one group or condition against another group or condition) that researchers conduct after they have already determined that there are at least some differences among a larger set of groups or conditions.
Prevalence: Prevalence is the proportion of people who have a given medical condition during a specified period time.
Prevalence ratio: A prevalence ratio is the ratio of expected counts. For example, imagine that Storrow Drive averages 3 “can opener” accidents per June and 18 such accidents per September. The September-to-June prevalence ratio would be 18/3 = 6.
Primary Prevention Strategy: Primary prevention aims to reduce the incidence of disease.
Proximal Risk Factors: Proximal risk factors refer to recent and/or immediate risk factors that could make a person vulnerable to a particular health condition.
µ (Population mean): By convention, lower case Greek letters are often used to indicate population parameters (the letter “mu” for mean) and upper case English letters indicate the sample parameters (capital M for mean).
Prefrontal Cortex: The area of the cortex most advanced in humans compared with other animals. This area primarily provides executive functions over other areas of the brain.
Probability: The ratio of the number of specific events to the number of all possible events (i.e., p = # specific / # specific + # other). Probabilities can range from zero (i.e., impossible) to one (i.e., every time). The probability of an event differs from the odds of an event in that the denominator for calculating odds is the non-events and the denominator for probability is the total of all events.
Probability Sample: Sample developed using some form of random selection. Examples include stratified sampling and cluster sampling.
Probit Regression Models: Similar to logistic models but use a log-normal transformation (the probit transformation) of the dependent variable. Where logit and logistic regression are appropriate when the categories of the dependent are equal or well dispersed, probit may be recommended when the middle categories have greater frequencies than the high and low tail categories, or with binomial dependents when an underlying normal distribution is assumed. As a practical matter, probit and logistic models yield the same substantive conclusions for the same data the great majority of the time.
Problem Gambling Severity Index: The Problem Gambling Severity Index, developed by Ferris and Wynne (2001), is a nine-question screener for problems with gambling.
Prosocial: Behaviors that are intended to help others (e.g., volunteering, sharing)
Prospective Study: In a prospective study, researchers follow a group of participants over time to document whether they experience certain outcomes, like developing a gambling problem. The researchers examine whether certain events predict certain outcomes. A major advantage is that participants are not asked to report on events that happened to them previously, as is the case with retrospective studies.
Q Statistic: Tests for the homogeneity of effects in a set of several studies. A significant Q statistic indicates significant heterogeneity among studies beyond the variability within studies. Q is not a measure of the degree of heterogeneity.
Huedo-Medina, T.B., Sanchez-Meca, J., Marın-Martınez, F., and Botella, J. (2006) Assessing Heterogeneity in Meta-Analysis: Q Statistic or I2 Index?, Psychological Methods, 11(2) 193–206.
Proxy: A variable that stands in for another unmeasured variable. Often, the association between a proxy and an outcome variable can appear causal when actually the proxy variable is associated with a third unmeasured variable that is the true causal factor.
QSU Brief: Represents Factors 1 and 2 from the full QSU, but is a 10-item questionnaire that takes less than two minutes to complete. Factor 1 is the intention and desire to smoke that is anticipated as a pleasant, enjoyable and satisfying behavior and Factor 2 is anticipation of relief from negative affect and nicotine withdrawal through smoking with an urgent desire to smoke.
Cox, L. S., Tiffany, S. T., & Christen, A. G. (2001). Evaluation of the brief questionnaire of smoking urges (QSU-brief) in laboratory and clinical settings. Nicotine & Tobacco Research, 3(1), 7-16.
Tiffany, S. T., & Drobes, D. J. (1991). The development and initial validation of a questionnaire on smoking urges. British Journal of Addiction, 86(11), 1467-1476.
Quartile: The segment of a sample representing a sequential quarter (25%) of a frequency distribution. The boundaries are at the 25th, 50th, and 75th percentiles.
Random Error: A wrong result due to chance. Unknown sources of variation are equally likely to distort the result in any direction.
Random-Effects Meta-Analysis: A model used when the results of studies included in a meta-analysis are thought to belong to different populations. It is a process of adjusting the standard errors of the study-specific estimates to include the variation among the effects observed in the various studies. Put simply, this method is a way of standardizing differences in the observed results from different studies in order to make them more comparable to one another. The simplest and most common form is the DerSimonian and Laird model.
Randomized Controlled Trial: A randomized controlled trial is a rigorous scientific experiment where study subjects are randomly allocated into groups to receive or not to receive the medication/intervention under investigation.
Rate Ratio: The ratio of the rate in the treatment population to the rate in the control population.
Recall Bias: Bias due to differences in accuracy or completeness of memory.
Regression Analysis: A statistical process used by researchers to estimate the relationship between a dependent variable (Y) and one or more independent variables (X). It can describe how changes in the level of Y relate to changes in the level of X. Although researchers often use causal terminology (i.e., “the independent variable, parental drinking, predicted the dependent variable, adolescent drinking”) such causal relationships can only be inferred in specific circumstances, and not when researchers take measures of X and Y at the same time.
Regression Coefficient: Regression coefficients are variables or values that describe the relationships between the independent variables and the dependent variable. In many models, regression coefficients are used to describe the expected change in the dependent variable given changes in the independent variables. Regression coefficients often represent rates of change. For example, in a study of salaries, one coefficient could represent an increase in expected salary associated with having one more year of experience.
Regression to the Mean: The tendency of extreme values to become less extreme (closer to the average) when they are reassessed.
Relative Risk: Relative risk – or risk ratio – is the ratio of the probability of an event under one condition (or group) to the probability under another condition. Risk ratio is interpretable as a comparative quantity; the RR comparing Group A with an event probability of .6 to Group B with a probability of .3 is 2.0. The same risk ratio would result if the probabilities were ten times smaller (i.e., .06 to .03). In both comparisons, the risk ratio indicates that the event is twice more likely to occur in Group A than Group B. Depending on the choice of the event, risk ratio could be a “risk” if the event is untoward, cancer say, or it could be a “benefit” if the event was desired, not getting cancer.
Replication: The term “replicate” has two general meanings in social science research. A direct replication refers to attempting to recreate the results of a scientific study by following the same steps that the original team of researchers used. This is typically done when researchers want to know if they can confirm results of a study. A conceptual replication is when researchers attempt to confirm not the results of a study, but an underlying hypothesis. They do so using different methods than the original study. For instance, researchers might sample from a different universe of participants (e.g., people living in the general community versus college students). Or the might manipulate an independent variable in a slightly different way–for instance, by inducing a sad mood by asking participants to watch a sad movie, rather than asking them to write about a sad experience in their life. The idea is to find out if the original pattern of results can still emerge under different experimental conditions.
Representative Sample: A group of participants that match a population based on a set of criteria, usually demographics. For example, if the population of a country is 70% female and 30% male, then researchers would want to recruit enough participants of each gender to match these percentages. This is often done through random sample, but can also be achieved through stratified sampling.
Resilience: A person’s ability to adapt positively (i.e. not engaging in risky behavior) in the face of adversity (i.e. prior exposure to risky behavior).
Response Rate: The proportion, percentage, or fraction of individuals who reply to inquiries that have been directed to all individuals in a population, or a representative sample of them. The validity of findings or results and conclusions derived from them is dependent on the response rate. If the response rate is low, i.e., if there are large proportions of non-responders, the validity of the results is dubious, even if impeccable sampling methods have been used, because of the magnitude of random error.
Retrospective: A type of interviewing where participants are respond to questions about past behaviors. For example, participants might respond to questions about lifetime alcohol use behaviors.
Reward Pathway: The dopaminergic pathway in the brain that prompts positive feelings in response to certain behaviors or events. Areas of the brain found along the reward pathway include, among others, the ventral tegmentum, the nucleus accumbens, and the prefrontal cortex.
Risk Factor: A behavior or characteristic that is shown to be associated with health conditions.
Salience: How much something (object, idea, or stimulus) stands out to you, or how likely you are to pay attention to it. For example, imagine you are at a party and there are many conversations going on around you. The conversations are all indistinct until you clearly hear someone say your name. The reason why you can make out your name from the rest of the background noise is because your name is more salient to you than the other words in the conversation.
Sample: A sub-group of observations selected from the study population. For example, researchers interested in understanding the population of United States college students might select three or four schools (i.e., a sample) to represent this population.
Secondary Data: Data are considered secondary if the researchers are not the people who originally collected them. For example, U.S. census data is collected by the U.S. Census Bureau. When researchers use that census data for their studies, the researchers consider it secondary data.
Secondary Prevention Strategy: Secondary prevention aims to reduce the prevalence of disease by shortening its duration.
Selection Bias: Error due to systematic differences in characteristics between those who take part in a study and those who do not. Selection bias affects conclusions and generalizations that are made regarding the study sample.
Self-Fulfilling Prophecy: The process by which one’s expectations about a person eventually lead that person to behave in ways that confirm those expectations.
Self-Limit Programs: Programs offered by casinos or Internet gambling sites that impose wagering or deposit limits.
Self-Report: A report about one’s thoughts or behavior provided by the subject of the research. Self-report measures have the advantage of being easily administered. Also, they allow the participant to provide his or her own perspective. On the other hand, they can be biased by the tendency to present oneself in a favorable light, or by problems with memory and introspection.
Self-Selection: When eligibility for membership in sample or a study group is based on an individual characteristic, the sampling procedure is usually termed “self-selection.” For example, participants in a study comparing smokers to non-smokers would be assigned to one group or the other depending on their own decision to smoke or not. Self-selection generally precludes being able to control for the effect of other variables and observed group differences may not be due to the characteristic that determined selection.
Selection and Assignment: Selection refers to the process by which a sample is recruited from a population. A random selection of observations from the population will generally yield a sample that is representative of the entire population. Self-selection and other non-random recruitments will constrain the population and therefore, the ability to generalize the study findings. Assignment refers to the process by which the sample is further divided into experimental and control groups. A random assignment of the sample will generally yield groups that are similar to each other and the difference among them will be attributable to the experimental conditions. Non-random assignment procedures limit a study’s ability to control for non-experimental characteristics.
Sensitivity: An instrument’s ability to identify people who have the characteristic under investigation; (# of people with a characteristic who are correctly identified by instrument)/(# of people actually with characteristic).
Single-blind: A study design where the researcher knows which participants are receiving the placebo condition, but participant does not.
Skewed: An asymmetrical (non-normal) distribution in which values tail off more in one direction than the other.
Social desirability: The tendency of respondents to reply in a manner that will be viewed favorably by others, often measured via the Marlowe-Crowne Social Desirability Scale.
Snowball Sampling: A method of selecting for study the members of a “hidden” population (e.g., illicit drug users). Those participants initially identified are asked to name acquaintances who are added to the sample; these, in turn, are asked to name further acquaintances until enough participants are added for sufficient power for the proposed study.
Somatic Marker Hypothesis: Affective states associated with former experience (reward or punishment) are unconsciously encoded as somatic markers. The somatic markers are activated when we face a similar situation and help us guide decisions without any conscious effort.
Somatic States: The physiological changes that occur in the body in response to an emotionally charged stimulus that is present in the environment, or to a thought (memory) that has some emotional significance.
South Oaks Gambling Screen (SOGS): A 20-item self-report screen that assesses lifetime gambling symptoms and can be used to identify individuals that are in remission.
Spatial cluster analysis: Spatial cluster analysis is used in geographic information systems (GIS) to determine how a variable clusters together across geographic units, such as neighborhoods, cities, states or countries. For example, a researcher may be interested in assessing which neighborhoods have higher rates of opioid dependence. They could obtain data on the opioid dependence rate variable for each neighborhood in a city and then use spatial cluster analysis to determine which groups of neighborhoods have higher dependence rates when compared to other groups of neighborhoods.
Lesieur HR, Blume SB (1987). The South Oaks Gambling Screen (SOGS): a new instrument for the identification of pathological gamblers. The American Journal of Psychiatry 144, 1184–8.
Specificity: An instrument’s ability to rule out people who do not have the characteristic under investigation; (# of people without characteristic who are correctly identified by instrument)/(# of people actually without characteristic).
Spurious: A situation in which an apparent relationship between two or more variables is lacking validity.
Standard Error: Statistics from a sample of the population will vary from sample to sample. The standard error is a measure of the size of the variation in the sample statistic over all samples of the same size as the study sample. The greater the study sample size, the smaller the variation across samples. The size of the standard error determines the range of values that will include the population parameter. Smaller standard errors lead to more precise estimates of the characteristic in the population.
State: A temporary behavior or feeling in a given moment. Contrast this with a trait, which is an enduring characteristic behavior or feeling. For example, being asked to take a pop quiz might increase your state anxiety at that moment, but your tendency to become anxious during pop quizzes would be part of your trait anxiety.
Statistical power: The probability that an experiment will find an effect if that effect exists in the total population. The number of observations in the study (i.e., sample size) sample greatly influences statistical power.
Statistical Significance: Researchers often engage in significance testing in order to estimate the probability of making a Type I error—that is, claiming that a relationship exits when, in reality, no such relationship exists. For example, a researcher might make a Type I error by claiming that women underperform men on a test of negotiation skills, when no such difference really exists. Researchers engage in significance testing first by computing a statistical test (such as a t-test or ANOVA). The values of statistical tests are associated with p-values—the larger the test value, the smaller the p-value, or probability of making a Type I error. Sample size also plays an important role: a statistical test result might have a p-value of 0.05 with a sample size of 5, or a p-value of 0.025 with a sample size of 45. The tradition is to conclude that a finding is “statistically significant” if the p-value is less than 0.05. However, it is important not to define the results of a statistical test purely in terms of statistical significance. A result that is statistically significant is not necessarily practically or clinically significant. Other indicators, especially effect size, can tell us a lot about the true strength of any effect uncovered.
Stigma: The physical or mental characteristics of a person which may be viewed as socially undesirable and are treated with bias (e.g., a stereotype, rejection, discrimination). For example, the belief that treatment seeking indicates that someone is “crazy”, “unstable”, or “dangerous”.
Adapted from Blaine, B. (2000). The psychology of diversity: Perceiving and experiencing social difference. Mountain View, CA: Mayfield Publishing.
Stimulus: An object or sensation that triggers a response in an organism (person, animal, plant, etc.). For example, a flashing light is a visual stimulus; a chime is an auditory stimulus; a puff of air on your face is a tactile stimulus.
Stratified Sampling: A method of sampling from a population in which the researcher divides the members of the population into mutually exclusive subgroups, or strata, before sampling. All possible strata must be represented. For example, a researcher studying adults might identify strata based on age (e.g., 18-25, 26-35, 36-45, and so on). Once the researcher identifies strata for sampling, he or she begins to sample within each stratum, often using random sampling. An advantage of stratified sampling is that it improves the representativeness of the sample.
Stroop Effect: The Stroop Effect (also, Stroop Test) is based on a phenomenon that most people read a printed word more quickly and automatically than they are able to name the color in which that word is printed. When presented with a list of written color names that differ from the color ink in which they are printed (e.g. the word “blue” written in red ink), a person will be prone to produce the color name rather than the ink color; overriding this impulse requires response inhibition. Researchers use responses to the Stroop task, particularly the reaction time and error rates, to measure response inhibition in studies of various neuropsychological conditions, impulsivity, attention and other cognitive phenomena. The Stroop test is named after its developer, John Stroop.
Structural Equation Modeling: An analytic technique used to test hypothesized relationships among latent variables representing abstract concepts, which are measured with observed indicator variables. Researchers first use factor analysis to determine how well measured indicator variables represent the latent variables of interest. Next, sets of equations are estimated to determine the strength of the effects (effect sizes), statistical significance and goodness of model fit for the structural equation model.
For example, if a study tested the relationship between the latent concepts of socioeconomic status and depression, observed measures of income and education could measure socioeconomic status. To measure the latent concept of depression, the study could use observed measures of extreme loneliness and sadness in the past 30 days. The model would then empirically test if there is actually a relationship between the latent variables and the strength of this relationship. Structural equation modeling can test for causal relationships among variables and can be used with either cross-sectional and longitudinal data.
Structured Clinical Interview for Pathological Gambling (SCI-PG): An interview questionnaire used to examine reported symptoms and diagnose pathological gambling.
Grant JE, Steinberg MA, Kim SW, Rounsaville BJ, Potenza MN (2004). Preliminary validity and reliability testing of a structured clinical interview for pathological gambling. Psychiatric Research 128, 79–88.
Subclinical Disorder: Some people might not qualify for a full diagnosis of a psychiatric disorder, but still experience one or several symptoms that cause them significant social-, functional-, or health-related impairment. For example, someone might experience financial harms related to their drinking behaviors that cause them significant problems, but not experience any other symptoms that qualify them for a diagnosis of alcohol use disorder. These individuals might be considered to have a subclinical alcohol use disorder.
Survival analysis: Allows us to estimate the hazard (or risk) of death, or other event of interest, past a certain time for individuals with certain characteristics. For example, researchers can ask whether men and women have different risks for developing lung cancer based on their cigarette smoking? Survival models, in which one of the variables is time, are similar to ordinary regression models. The model identifies the probability that the time of death is later than some specified time. It provides coefficients for each of the predicting variables. A positive regression coefficient for a variable means that the hazard is greater, and thus the prognosis worse. Conversely, a negative regression coefficient implies a better prognosis for patients with higher values of that variable. The choice of a specific model (e.g., the Kaplan-Meier (product-limit) Estimator, the Cox Proportional Hazards Model, the Weibull Fit.) mostly depends on the underlying assumptions about the data distribution and the extent of data censoring problems.
Systematic Error: A wrong result due to bias. Sources of variation will distort the result in one direction.
Systematic Review: A type of study where researchers investigate a question by using standardized methods to collect all the available research on the topic and evaluate the results of each paper to create a summary. For example, researchers might be curious as to whether cognitive-behavioral therapy is effective for treating depression. The researchers might gather as many studies of CBT and depression as they can, and then score each paper on how effective the treatment was. The researchers would then summarize the findings to say how many studies were successful, and discuss the strengths and limitations of the pool of studies they reviewed.
Tell: A behavior or change in behavior that may give astute opponents clues about a poker player’s hole cards or future plans for the hand. Examples include facial tells (e.g., looking away when holding a strong hand), arm/hand tells (e.g., slamming a bet down to intimidate when bluffing), and betting tells (e.g., only betting big with extremely strong hands).
Tertiary Prevention Strategy: Aims to reduce the number and/or impact of disease complications.
Test-Retest Reliability: An index of the extent to which the result of a psychological test changes over time. If the construct being measured is not expected to change over time, the researcher should expect to observe high test-rest reliability. For example, a person’s level of introversion should not change dramatically from one day to the next. If that person’s score on a measure of introversion changes dramatically from day-to-day — if it has low test-retest reliability–this suggests that there is something wrong with the measure.
Tetrachoric Correlation: Assesses the relationship between dichotomous variables (i.e. variables with only two possible responses, such as yes or no). These correlations assume an underlying continuous distribution of dichotomous variables.
Tetrahydrocannabinol (THC): The principal psychoactive component of the cannabis plant.
Thematic Analysis: A qualitative research method that is used to discover major concepts in interviews, focus groups and written text. In thematic analysis, researchers closely read transcribed text to analyze, identify and interpret key themes that appear frequently or that are particularly salient. For example, a researcher interested in reasons why people drink alcohol might conduct a focus group, transcribe participant responses from the session, and then analyze the responses to see which reasons are discussed most often or reasons that are strongly emphasized by participants.
Thin-Slicing: Drawing conclusions or predictions based on small amounts (“thin slices”) of experience.
Titration: Adjustment of dosage to obtain best serum level to get efficacy with the least side effects.
Trait: An enduring characteristic behavior or feeling. Contrast this with a state, which is a temporary behavior or feeling in a given moment. For example, a person with high trait anxiety has a greater overall tendency to experience state anxiety in response to different situations.
Transtheoretical Model (TTM): An approach to therapy which assesses a person’s readiness to engage in healthier behaviors, based on where they fit in a series of “stages of change.” The five stages of change are precontemplation, contemplation, preparation, action, and maintenance. This theory is commonly used in research pertaining to smoking cessation, weight loss, and adherence to medication. James Prochaska and colleagues developed the TTM in the early 1980s.
Treatment Group: Researchers design experiments to eliminate (control for) the effect of non-experimental variables on the results. For example, a study may compare the outcomes of two groups that differ only because one group received the experimental condition (the treatment group) and the other did not (the control group). Medication trials are often “placebo controlled” by using a control group that is treated similarly in all ways except they receive a non-active medication (placebo) instead of the active medication being studied (with the treatment group).
Tukey’s Honest Significant Difference (HSD) Test: A procedure for testing whether the means of different groups are significantly different. Tukey’s HSD compares the mean of each group to the means of each of the others.
Twelve-step Program: Twelve-step programs are addiction treatment programs where people with similar substance abuse problems meet regularly to assist each other with the recovery process. Ideas behind the twelve-step process include (1) acceptance that willpower alone is insufficient to overcome the problem, (2) willingness to use the support structure of other recovering individuals, and (3) active involvement in 12-step meetings.
Two-Stage Cluster Sample: Consists of selecting a, usually random, sample of natural clusters of people such as households or schools and then selecting a random, representative sample of one or more people within these clusters.
Type I Error: Incorrectly rejecting the null hypothesis when it is true.
Type II Error: Failing to reject the null hypothesis when it is false.
Twin Study: A research design where researchers recruit pairs of twins (identical or fraternal) in order to determine which the extent to which traits, phenotypes, and disorders are attributable to environmental and genetic influences.
Validity: A psychological instrument’s validity is the extent to which it accurately measures what it is designed to measure. Said another way, a test and its scoring system are considered valid if the theory and evidence support the interpretations of the scores implied by the proposed uses of the test.
Value Bet: A bet where the gambler’s expected value is greater than $0. Some gamblers will analyze different betting options or combinations looking for value bets. The idea is that a gambler who makes only value bets will make money in the long run, provided that he is not ruined by any short-term losing streaks.
Ventromedial: Of, relating to, or involving both the front and the middle.
Vignette: A hypothetical situation presented to participants in a survey. Participants read the vignette, and then answer questions about their perceptions and impressions of the situation described and the characters involved.
Weighted Least Squares Regression: In standard least squares regression, the researchers assumes that the response variable has the same measurement error or variability, no matter what values the factors or independent variables take. In some applications, however, the measurement error varies with the independent variables. In these cases, weighted least squares regression accounts for this variability.
Yale Brown Obsessive Compulsive Scale Modified for Pathological Gambling (PG-YBOCS): A 10-item scale, administered by a clinician, that measures past-week gambling symptoms.
Pallanti S, DeCaria CM, Grant JE, Urpe M, Hollander E (2005). Reliability and validity of the pathological gambling adaptation of the yale-brown obsessive–compulsive scale (PG-YBOCS). Journal of Gambling Studies 21, 431–43.
Z score: Identifies the distance that an original (raw) score is from the mean. The distance is measure in standard deviation units, e.g., a Z score of 1.0 indicates that the raw score was one standard deviation greater than the mean.